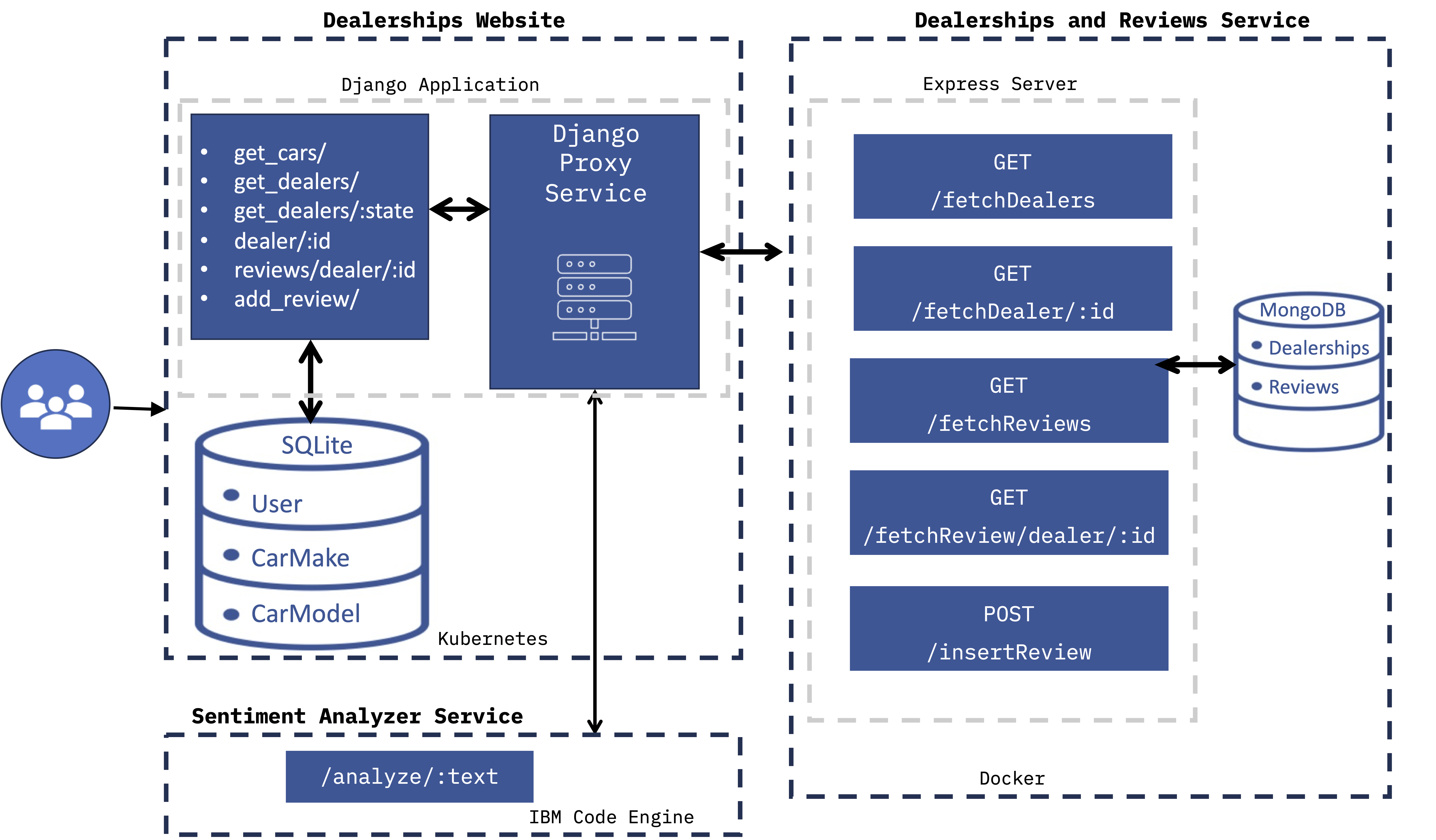
This project focused on analyzing an HR dataset to uncover insights into employee retention and build predictive models for identifying key turnover factors. Initial data exploration included loading a 14,999-row dataset, renaming columns for clarity, and removing 3,008 duplicate rows. Missing values were checked, and data types were reviewed to ensure proper preprocessing.
Key Analysis Steps and Visualizations:
1. Outlier Detection: Using boxplots and IQR, 824 outliers in tenure were flagged (outside 1.5-5.5 years).
2. Retention Analysis: Analysis of the left column revealed 16.6% of employees had left. Visualizations like boxplots, histograms, and scatter plots highlighted trends in project counts, average monthly hours, and satisfaction levels, showing that higher workloads increased turnover.
3. Tenure and Salary Insights: Tenure distribution showed lower satisfaction (mean: 0.44) for those who left, compared to retained employees (mean: 0.67). Histograms segmented by tenure and salary indicated higher turnover among short-tenured, low-salary employees.
4. Department Retention Trends: Counts of stayed/left employees across departments revealed varied retention rates, emphasizing the need for department-specific strategies.
Data Preparation for Modeling:
• Salary was encoded ordinally, and departments were dummy-encoded for model compatibility.
• A correlation heatmap identified significant predictors like satisfaction level and average monthly hours.
• Outliers were removed for a clean dataset used in logistic regression modeling.
• The dataset is split into training (X_train, y_train) and testing (X_test, y_test) sets using train_test_split() with a 25% test size, stratified on y to maintain the target distribution, and a random_state for reproducibility.
Predictive Modeling Highlights:
1. Logistic Regression:
○ A logistic regression model log_clf is instantiated with random_state=42 and max_iter=500 and fitted on the training data.
○ Precision, recall, f1-score, and support for both classes: employees predicted to stay and to leave.
○ The overall accuracy is 82%, with a macro average f1-score of 0.61, showing lower performance for predicting employees who left (precision 0.44, recall 0.26).
2. Decision Tree Classifier:
○ Optimized with GridSearchCV, resulting in best parameters: max_depth=6, min_samples_leaf=2, min_samples_split=6.
○ Achieved an AUC score of 0.9587, with precision at 0.857 and recall at 0.904, confirming reliable detection of turnover.
3. Random Forest Classifier:
○ Hyperparameters (max_depth=5, n_estimators=300, max_samples=0.7) were found through optimization.
○ Reached an AUC of 0.9648, slightly outperforming the decision tree.
○ Feature importance analysis showed satisfaction level, average monthly hours, and tenure as top predictors.
Interpretability and Insights:
• Visual plots of feature importances from both models identified key factors driving employee retention.
• Important features were plotted based on Gini importance, with results suggesting that factors like satisfaction level, average monthly hours, and tenure play significant roles in determining employee turnover.
Overall, this analysis utilized the effective use of data exploration, visualization and machine learning techniques to model company data such as employee retention, providing actionable insights for HR strategies aimed at reducing turnover. The results underscore the importance of job satisfaction, workload, and tenure in predicting employee departure, offering a data-driven approach to HR management.